Building a personal AI assistant is no longer reserved for the tech giants. With Python’s ecosystem, developers can build custom voice-enabled assistants for specific needs – whether it’s automation, managing schedules or answering complex questions.
You’ll learn in this guide the entire process, from basic setup to advanced features, providing steps along the way.
This guide assumes you have basic Python programming knowledge and familiarity with installing packages. You don’t need machine learning expertise – we’ll use existing libraries and models while explaining key concepts as we go.
By the end of this project, you’ll have a functional AI assistant capable of:
- Processing voice commands
- Answering questions using AI models
- Managing your calendar and tasks
- Providing weather updates and news summaries
- Controlling compatible smart home devices
Let’s begin!
Section 1: Setting Up Your Environment
Creating a dedicated environment ensures your assistant’s dependencies don’t conflict with other projects. Let’s set everything up properly.
First, ensure you have Python 3.8 or newer installed. You can check your version by running:
python --versionNext, create a virtual environment to keep your dependencies isolated:
# Create a new directory for your project
mkdir personal_assistant
cd personal_assistant
# Create and activate a virtual environment
python -m venv venv
# On Windows
venv\Scripts\activate
# On macOS/Linux
source venv/bin/activateWith your environment activated, install the core dependencies:
pip install SpeechRecognition pyttsx3 openai requests python-dotenv spacy transformers PyAudio nltk google-api-python-clientThis installs:
- SpeechRecognition: For converting speech to text
- pyttsx3: For text-to-speech capabilities
- openai: To interact with GPT models
- requests: For making API calls
- python-dotenv: To securely store API keys
- spacy and nltk: For natural language processing
- transformers: For accessing Hugging Face models
- PyAudio: For microphone input processing
- google-api-python-client: For calendar integration
Create a .env file in your project directory to store API keys:
OPENAI_API_KEY=your_key_here
WEATHER_API_KEY=your_key_here
NEWS_API_KEY=your_key_hereNow create a simple requirements.txt file for future reference:
pip freeze > requirements.txtWith our environment set up, we can now move on to designing our assistant’s architecture.
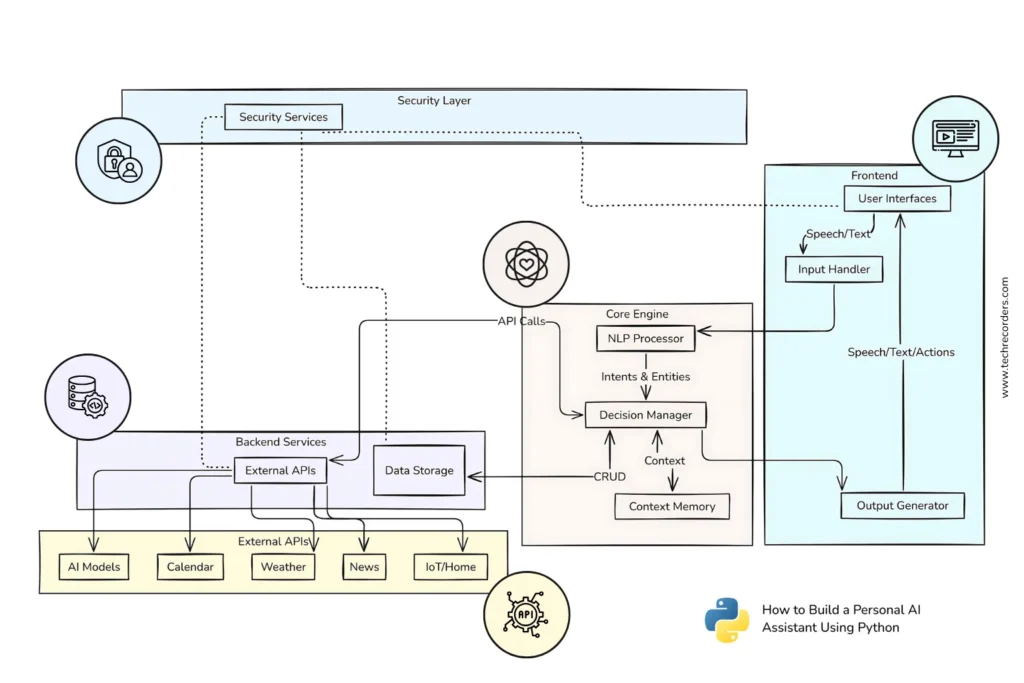
Section 2: Designing Your Assistant’s Architecture
A well-designed architecture makes your assistant easier to build, debug, and extend. Let’s create a modular system with clearly defined components.
The core architecture follows this pattern:
- Input Handler: Processes voice or text input from the user
- Intent Classifier: Determines what the user wants to do
- Skill Modules: Specialized components for specific tasks (weather, calendar, etc.)
- Response Generator: Creates natural language responses
- Output Handler: Delivers responses via text or speech
Start by creating a project structure:
personal_assistant/
├── main.py
├── .env
├── requirements.txt
├── assistant/
│ ├── __init__.py
│ ├── input_handler.py
│ ├── intent_classifier.py
│ ├── response_generator.py
│ ├── output_handler.py
│ └── memory.py
├── skills/
│ ├── __init__.py
│ ├── weather.py
│ ├── calendar_manager.py
│ ├── news.py
│ ├── general_knowledge.py
│ └── task_manager.py
└── utils/
├── __init__.py
├── config.py
└── logger.pyIn main.py, we’ll create the orchestrator that ties everything together:
from assistant.input_handler import InputHandler
from assistant.intent_classifier import IntentClassifier
from assistant.response_generator import ResponseGenerator
from assistant.output_handler import OutputHandler
from assistant.memory import ConversationMemory
class Assistant:
def __init__(self, voice_mode=True):
self.input_handler = InputHandler(voice_enabled=voice_mode)
self.intent_classifier = IntentClassifier()
self.response_generator = ResponseGenerator()
self.output_handler = OutputHandler(voice_enabled=voice_mode)
self.memory = ConversationMemory()
self.running = False
def start(self):
self.running = True
self.output_handler.output("Hello! I'm your personal assistant. How can I help you today?")
while self.running:
# Get user input
user_input = self.input_handler.get_input()
# Store in conversation memory
self.memory.add_user_message(user_input)
# Determine intent and entities
intent, entities = self.intent_classifier.classify(user_input, self.memory.get_context())
# Process the intent and generate a response
response = self.process_intent(intent, entities)
# Store assistant response in memory
self.memory.add_assistant_message(response)
# Output the response
self.output_handler.output(response)
def process_intent(self, intent, entities):
# Import skills on demand to keep startup fast
if intent == "exit":
self.running = False
return "Goodbye! Have a great day."
elif intent == "weather":
from skills.weather import get_weather
return get_weather(entities)
elif intent == "calendar":
from skills.calendar_manager import process_calendar_request
return process_calendar_request(entities)
# Add more intents as needed
else:
from skills.general_knowledge import get_answer
return get_answer(self.memory.get_conversation_history())
if __name__ == "__main__":
assistant = Assistant(voice_mode=True)
assistant.start()This architecture:
- Maintains conversation context through memory
- Loads skill modules only when needed
- Keeps concerns separated for easier development
- Allows for both text and voice interaction modes
The modular design also makes it easy to add new skills without modifying core functionality, following the open-closed principle of software design.
Section 3: Building the Voice Interface
Voice capabilities transform how users interact with your assistant. Let’s implement speech recognition and text-to-speech functionality.
First, create the input handler in assistant/input_handler.py:
import speech_recognition as sr
class InputHandler:
def __init__(self, voice_enabled=True):
self.voice_enabled = voice_enabled
if voice_enabled:
self.recognizer = sr.Recognizer()
self.microphone = sr.Microphone()
# Adjust for ambient noise
with self.microphone as source:
self.recognizer.adjust_for_ambient_noise(source)
# Set energy threshold for detecting speech
self.recognizer.energy_threshold = 4000
def get_input(self):
if self.voice_enabled:
return self._get_voice_input()
else:
return input("You: ")
def _get_voice_input(self):
print("Listening...")
with self.microphone as source:
try:
audio = self.recognizer.listen(source, timeout=5, phrase_time_limit=5)
print("Processing speech...")
# Try using multiple recognition services for better reliability
try:
text = self.recognizer.recognize_google(audio)
return text
except:
try:
# Fallback to another service
text = self.recognizer.recognize_sphinx(audio)
return text
except:
print("Sorry, I didn't catch that.")
return self.get_input()
except sr.WaitTimeoutError:
print("No speech detected. Please try again.")
return self.get_input()Next, implement the output handler in assistant/output_handler.py:
import pyttsx3
class OutputHandler:
def __init__(self, voice_enabled=True):
self.voice_enabled = voice_enabled
if voice_enabled:
self.engine = pyttsx3.init()
# Customize voice settings
voices = self.engine.getProperty('voices')
self.engine.setProperty('voice', voices[1].id) # Index 1 is usually a female voice
self.engine.setProperty('rate', 180) # Slightly faster than default
def output(self, text):
print(f"Assistant: {text}")
if self.voice_enabled:
self.engine.say(text)
self.engine.runAndWait()To improve voice recognition accuracy:
- Use a good microphone
- Implement wake word detection to avoid processing background conversations
- Add noise cancellation processing
- Consider implementing a confirmation step for critical commands
For a more advanced setup, add wake word detection using Porcupine or Snowboy libraries before activating full speech recognition. This saves processing power and prevents accidental activations.
Section 4: Natural Language Processing
The intent classifier is the brain of your assistant, determining what the user wants. We’ll use spaCy for entity extraction and a simple classifier for intent recognition.
Create assistant/intent_classifier.py:
import spacy
import re
class IntentClassifier:
def __init__(self):
# Load spaCy model
self.nlp = spacy.load("en_core_web_sm")
# Define intent patterns
self.intent_patterns = {
"weather": [r"weather", r"temperature", r"forecast", r"raining", r"sunny"],
"calendar": [r"calendar", r"schedule", r"meeting", r"appointment", r"event"],
"news": [r"news", r"headlines", r"current events"],
"task": [r"remind me", r"to-do", r"task", r"list"],
"greeting": [r"hello", r"hi", r"hey", r"good morning", r"good afternoon"],
"exit": [r"exit", r"quit", r"goodbye", r"bye", r"stop"]
}
def classify(self, text, context=None):
"""
Determine the user's intent and extract relevant entities
Args:
text (str): The user's input text
context (dict): Previous conversation context
Returns:
tuple: (intent, entities)
"""
text = text.lower()
doc = self.nlp(text)
# Extract entities
entities = {
"dates": [],
"times": [],
"locations": [],
"people": [],
"query": text # Store original query for fallback to AI
}
# Extract entities using spaCy
for ent in doc.ents:
if ent.label_ == "DATE" or ent.label_ == "TIME":
if ent.label_ == "DATE":
entities["dates"].append(ent.text)
else:
entities["times"].append(ent.text)
elif ent.label_ == "GPE" or ent.label_ == "LOC":
entities["locations"].append(ent.text)
elif ent.label_ == "PERSON":
entities["people"].append(ent.text)
# Match intents based on patterns
for intent, patterns in self.intent_patterns.items():
for pattern in patterns:
if re.search(pattern, text):
return intent, entities
# If no explicit intent is found, use context or default to general knowledge
if context and "current_intent" in context:
# Continue previous intent if relevant
return context["current_intent"], entities
return "general_knowledge", entitiesFor more advanced intent classification, consider implementing a machine learning approach:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import LinearSVC
import joblib
import os
class MLIntentClassifier:
def __init__(self, model_path="models/intent_classifier.pkl"):
self.nlp = spacy.load("en_core_web_sm")
if os.path.exists(model_path):
self.model = joblib.load(model_path)
self.vectorizer = joblib.load(model_path.replace("intent_classifier.pkl", "vectorizer.pkl"))
else:
# Default to pattern matching if no model exists
self.model = None
self.vectorizer = None
self.pattern_classifier = IntentClassifier()
def classify(self, text, context=None):
# Extract entities first
doc = self.nlp(text)
entities = self._extract_entities(doc)
# If we have a trained model, use it
if self.model and self.vectorizer:
# Transform text
text_features = self.vectorizer.transform([text.lower()])
# Predict intent
intent = self.model.predict(text_features)[0]
return intent, entities
else:
# Fall back to pattern matching
return self.pattern_classifier.classify(text, context)
def _extract_entities(self, doc):
# Same entity extraction as before
# ...To train this model, you’d need labeled examples of user queries for each intent. You can start with a small dataset and expand it over time as you collect more user interactions.
Section 5: Implementing Core Features
Now let’s implement some essential skills for your assistant. We’ll start with weather forecasting.
Create skills/weather.py:
import requests
import os
from datetime import datetime
from dotenv import load_dotenv
load_dotenv()
def get_weather(entities):
"""
Get current weather or forecast based on entities
Args:
entities (dict): Contains locations and dates
Returns:
str: Weather information
"""
api_key = os.getenv("WEATHER_API_KEY")
if not api_key:
return "I'm sorry, but I need a weather API key to check the weather."
# Default to user's location if no location specified
location = entities["locations"][0] if entities["locations"] else "New York"
# Check if forecast or current weather is requested
is_forecast = any(forecast_term in entities["query"]
for forecast_term in ["forecast", "tomorrow", "week", "days"])
if is_forecast:
return _get_forecast(location, api_key)
else:
return _get_current_weather(location, api_key)
def _get_current_weather(location, api_key):
"""Get current weather conditions"""
base_url = "https://api.openweathermap.org/data/2.5/weather"
# Make request to OpenWeatherMap API
params = {
"q": location,
"appid": api_key,
"units": "imperial" # Use "metric" for Celsius
}
try:
response = requests.get(base_url, params=params)
data = response.json()
if response.status_code == 200:
# Extract weather information
temp = data["main"]["temp"]
feels_like = data["main"]["feels_like"]
description = data["weather"][0]["description"]
humidity = data["main"]["humidity"]
wind_speed = data["wind"]["speed"]
# Format response
return (f"Currently in {location}, it's {temp}°F with {description}. "
f"Feels like {feels_like}°F. Humidity: {humidity}%, "
f"Wind speed: {wind_speed} mph.")
else:
return f"I couldn't find weather information for {location}. Please try another location."
except Exception as e:
return f"Sorry, I encountered an error getting the weather: {str(e)}"
def _get_forecast(location, api_key):
"""Get 5-day weather forecast"""
base_url = "https://api.openweathermap.org/data/2.5/forecast"
# Similar implementation as current weather but processes forecast data
# ...Next, let’s implement a calendar manager in skills/calendar_manager.py:
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
import datetime
import os
import pickle
# Define the scopes for Google Calendar API
SCOPES = ['https://www.googleapis.com/auth/calendar']
def process_calendar_request(entities):
"""
Handle calendar-related requests
Args:
entities (dict): Contains dates, times, people, and the original query
Returns:
str: Response to calendar request
"""
# Determine the specific action (list, add, delete)
query = entities["query"].lower()
if any(term in query for term in ["list", "show", "what", "appointments"]):
return list_events(entities)
elif any(term in query for term in ["add", "create", "schedule", "new"]):
return add_event(entities)
elif any(term in query for term in ["delete", "remove", "cancel"]):
return delete_event(entities)
else:
return "I'm not sure what you want to do with your calendar. You can ask me to list, add, or remove events."
def get_calendar_service():
"""Set up and return Google Calendar API service"""
creds = None
# Check if we have token.pickle file with credentials
if os.path.exists('token.pickle'):
with open('token.pickle', 'rb') as token:
creds = pickle.load(token)
# If no credentials available or they're invalid, authenticate
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
'credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
# Save the credentials for the next run
with open('token.pickle', 'wb') as token:
pickle.dump(creds, token)
return build('calendar', 'v3', credentials=creds)
def list_events(entities):
"""List upcoming calendar events"""
try:
service = get_calendar_service()
# Get start time from entities or use now
now = datetime.datetime.utcnow().isoformat() + 'Z'
# Call the Calendar API
events_result = service.events().list(
calendarId='primary',
timeMin=now,
maxResults=10,
singleEvents=True,
orderBy='startTime'
).execute()
events = events_result.get('items', [])
if not events:
return "You don't have any upcoming events scheduled."
# Format the events list
response = "Here are your upcoming events:\n"
for event in events:
start = event['start'].get('dateTime', event['start'].get('date'))
# Convert to more readable format
if 'T' in start: # This is a datetime
start_dt = datetime.datetime.fromisoformat(start.replace('Z', '+00:00'))
start_str = start_dt.strftime("%A, %B %d at %I:%M %p")
else: # This is a date
start_dt = datetime.datetime.fromisoformat(start)
start_str = start_dt.strftime("%A, %B %d (all day)")
response += f"- {event['summary']} on {start_str}\n"
return response
except Exception as e:
return f"I had trouble accessing your calendar: {str(e)}"
def add_event(entities):
"""Add a new calendar event"""
# Implementation for adding events
# ...
def delete_event(entities):
"""Delete a calendar event"""
# Implementation for deleting events
# ...These are just two examples of skills you can implement. Other core features would include:
- News summarization using news API services
- Task management with local storage
- General knowledge powered by AI models
Section 6: Leveraging AI Models
To make your assistant truly intelligent, leverage large language models like GPT. Create a general knowledge handler in skills/general_knowledge.py:
import os
import openai
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
def get_answer(conversation_history):
"""
Use AI to answer general knowledge questions
Args:
conversation_history (list): List of past messages for context
Returns:
str: AI-generated response
"""
if not openai.api_key:
return "I'm sorry, but I need an OpenAI API key to answer general knowledge questions."
try:
# Format conversation history for the API
messages = []
# Add system message to set the assistant's behavior
messages.append({
"role": "system",
"content": "You are a helpful personal assistant. Provide concise, accurate responses."
})
# Add conversation history (up to last 5 exchanges to save tokens)
for i, entry in enumerate(conversation_history[-10:]):
role = "user" if i % 2 == 0 else "assistant"
messages.append({"role": role, "content": entry})
# Make request to OpenAI
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
max_tokens=150,
temperature=0.7,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
# Extract and return the response
return response.choices[0].message.content.strip()
except Exception as e:
return f"I'm having trouble connecting to my knowledge source right now: {str(e)}"For local AI capabilities, you can use smaller models with the Hugging Face Transformers library:
from transformers import pipeline
class LocalAI:
def __init__(self):
# Load a smaller model suitable for running locally
self.generator = pipeline('text-generation', model='gpt2')
def generate_response(self, prompt, max_length=100):
"""Generate text response using local model"""
try:
response = self.generator(prompt, max_length=max_length, num_return_sequences=1)
return response[0]['generated_text'][len(prompt):].strip()
except Exception as e:
return f"Error generating response: {str(e)}"To optimize your AI usage:
- Implement caching for common questions
- Use smaller models for simpler tasks
- Create fallback mechanisms when API services are unavailable
- Implement rate limiting to control costs
Section 7: Creating a Personality
A personality makes your assistant more engaging. Implement this in assistant/memory.py:
class ConversationMemory:
def __init__(self, max_history=20):
self.conversation_history = []
self.max_history = max_history
self.context = {
"user_preferences": {
"name": None,
"location": None,
"preferred_temperature_unit": "fahrenheit",
"news_topics": []
},
"current_intent": None,
"last_entities": None
}
def add_user_message(self, message):
"""Add a user message to the conversation history"""
self.conversation_history.append(message)
self._trim_history()
def add_assistant_message(self, message):
"""Add an assistant message to the conversation history"""
self.conversation_history.append(message)
self._trim_history()
def get_conversation_history(self):
"""Get the entire conversation history"""
return self.conversation_history
def get_context(self):
"""Get the current conversation context"""
return self.context
def update_context(self, key, value):
"""Update a specific context value"""
# Handle nested dictionary keys like "user_preferences.name"
if "." in key:
main_key, sub_key = key.split(".")
if main_key in self.context and isinstance(self.context[main_key], dict):
self.context[main_key][sub_key] = value
else:
self.context[key] = value
def _trim_history(self):
"""Ensure history doesn't exceed max length"""
if len(self.conversation_history) > self.max_history:
# Remove oldest messages (keep pairs to maintain context)
self.conversation_history = self.conversation_history[-self.max_history:]To create a consistent personality, define response templates with varying styles:
class PersonalityEngine:
def __init__(self, personality_type="friendly"):
self.personality_type = personality_type
# Define personality traits and response templates
self.personalities = {
"friendly": {
"greeting": [
"Hi there! How can I help you today?",
"Hello! What can I do for you?",
"Hey! I'm here to assist you. What do you need?"
],
"not_understood": [
"I'm not quite sure I understood that. Could you rephrase?",
"I'm still learning, and that's a bit confusing for me. Mind trying again?"
],
"success": [
"Done! Anything else you need?",
"All set! What's next on your list?"
],
"apology": [
"I'm sorry about that. Let me try again.",
"My apologies, I made a mistake there."
]
},
"professional": {
# Professional personality templates
# ...
},
"concise": {
# Brief, to-the-point templates
# ...
}
}
def get_response_template(self, template_type):
"""Get a random response template based on personality and type"""
import random
templates = self.personalities.get(self.personality_type, {}).get(template_type, [])
if not templates:
# Fallback to friendly if the specific template isn't found
templates = self.personalities["friendly"].get(template_type, [
"I'm here to help." # Ultimate fallback
])
return random.choice(templates)
def format_response(self, template_type, response_content):
"""Format a response with a personality-appropriate template"""
template = self.get_response_template(template_type)
# For simple templates, just return them directly
if "{content}" not in template:
return template
# Otherwise, insert the content into the template
return template.format(content=response_content)Integrate this with your response generator to create consistent, personality-driven responses.
Section 8: Deployment Options
Let’s explore how to deploy your assistant on different platforms.
For desktop use, create a simple GUI using Tkinter:
import tkinter as tk
from tkinter import scrolledtext
import threading
from assistant.input_handler import InputHandler
from assistant.output_handler import OutputHandler
from assistant.intent_classifier import IntentClassifier
from assistant.memory import ConversationMemory
class AssistantGUI:
def __init__(self, root):
self.root = root
self.root.title("Personal AI Assistant")
self.root.geometry("600x400")
# Create GUI components
self.create_widgets()
# Initialize assistant components
self.input_handler = InputHandler(voice_enabled=False)
self.intent_classifier = IntentClassifier()
self.output_handler = OutputHandler(voice_enabled=True)
self.memory = ConversationMemory()
# Welcome message
self.display_message("Assistant: Hello! How can I help you today?", "assistant")
def create_widgets(self):
# Chat display area
self.chat_display = scrolledtext.ScrolledText(self.root, wrap=tk.WORD, width=70, height=20)
self.chat_display.grid(row=0, column=0, columnspan=2, padx=10, pady=10)
self.chat_display.config(state=tk.DISABLED)
# Input field
self.input_field = tk.Entry(self.root, width=50)
self.input_field.grid(row=1, column=0, padx=10, pady=10)
self.input_field.bind("<Return>", self.process_input)
# Send button
self.send_button = tk.Button(self.root, text="Send", command=self.process_input)
self.send_button.grid(row=1, column=1, padx=10, pady=10)
# Voice button
self.voice_button = tk.Button(self.root, text="🎤", width=3, command=self.voice_input)
self.voice_button.grid(row=1, column=1, padx=(0, 10), pady=10, sticky="w")
def display_message(self, message, sender):
self.chat_display.config(state=tk.NORMAL)
if sender == "user":
self.chat_display.insert(tk.END, f"You: {message}\n", "user")
else:
self.chat_display.insert(tk.END, f"{message}\n", "assistant")
# Auto-scroll to bottom
self.chat_display.see(tk.END)
self.chat_display.config(state=tk.DISABLED)
def process_input(self, event=None):
user_input = self.input_field.get()
if not user_input:
return
# Clear input field
self.input_field.delete(0, tk.END)
# Display user message
self.display_message(user_input, "user")
# Process in a separate thread to keep UI responsive
threading.Thread(target=self.process_message, args=(user_input,)).start()
def voice_input(self):
# Temporarily enable voice mode
temp_input_handler = InputHandler(voice_enabled=True)
# Disable buttons while listening
self.send_button.config(state=tk.DISABLED)
self.voice_button.config(state=tk.DISABLED)
# Get voice input in a separate thread
def listen():
user_input = temp_input_handler.get_input()
# Re-enable buttons
self.root.after(0, lambda: self.send_button.config(state=tk.NORMAL))
self.root.after(0, lambda: self.voice_button.config(state=tk.NORMAL))
if user_input:
# Display and process
self.root.after(0, lambda: self.display_message(user_input, "user"))
self.root.after(0, lambda: self.process_message(user_input))
threading.Thread(target=listen).start()
def process_message(self, user_input):
# Store in conversation memory
self.memory.add_user_message(user_input)
# Determine intent and entities
intent, entities = self.intent_classifier.classify(user_input, self.memory.get_context())
# Update context with current intent
self.memory.update_context("current_intent", intent)
self.memory.update_context("last_entities", entities)
# Process the intent
if intent == "exit":
response = "Goodbye! Have a great day."
self.root.after(2000, self.root.destroy) # Close after 2 seconds
elif intent == "weather":
from skills.weather import get_weather
response = get_weather(entities)
elif intent == "calendar":
from skills.calendar_manager import process_calendar_request
response = process_calendar_request(entities)
# Add more intents as needed
else:
from skills.general_knowledge import get_answer
response = get_answer(self.memory.get_conversation_history())
# Store assistant response in memory
self.memory.add_assistant_message(response)
# Display the response
self.root.after(0, lambda: self.display_message(response, "assistant"))
# Speak the response if enabled
self.output_handler.output(response)
# Run the GUI
if __name__ == "__main__":
root = tk.Tk()
app = AssistantGUI(root)
root.mainloop()For a headless Raspberry Pi deployment, create a service that runs automatically:
# assistant_service.py
import time
from assistant.input_handler import InputHandler
from assistant.intent_classifier import IntentClassifier
from assistant.response_generator import ResponseGenerator
from assistant.output_handler import OutputHandler
from assistant.memory import ConversationMemory
class AssistantService:
def __init__(self):
self.input_handler = InputHandler(voice_enabled=True)
self.intent_classifier = IntentClassifier()
self.response_generator = ResponseGenerator()
self.output_handler = OutputHandler(voice_enabled=True)
self.memory = ConversationMemory()
self.running = False
def start(self):
self.running = True
self.output_handler.output("Assistant service started. I'm listening for commands.")
while self.running:
# Listen for wake word
print("Waiting for wake word...")
# Here you would implement wake word detection
# For simplicity, we'll just listen continuously
# Get user input
user_input = self.input_handler.get_input()
if user_input:
print(f"Heard: {user_input}")
# Store in conversation memory
self.memory.add_user_message(user_input)
# Determine intent and entities
intent, entities = self.intent_classifier.classify(user_input, self.memory.get_context())
# Process the intent
if intent == "exit":
response = "Shutting down assistant service."
self.running = False
else:
# Process other intents as before
# ...
response = "Processing your request..." # Placeholder
# Output the response
self.output_handler.output(response)
# Sleep briefly to prevent CPU overuse
time.sleep(0.1)
if __name__ == "__main__":
service = AssistantService()
service.start()To set up as a systemd service on Raspberry Pi, create a file called /etc/systemd/system/assistant.service:
[Unit]
Description=Personal AI Assistant Service
After=network.target
[Service]
ExecStart=/home/pi/personal_assistant/venv/bin/python /home/pi/personal_assistant/assistant_service.py
WorkingDirectory=/home/pi/personal_assistant
StandardOutput=inherit
StandardError=inherit
Restart=always
User=pi
[Install]
WantedBy=multi-user.targetEnable and start the service:
sudo systemctl enable assistant.service
sudo systemctl start assistant.serviceFor mobile integration, create a simple Flask web service:
from flask import Flask, request, jsonify
from assistant.intent_classifier import IntentClassifier
from assistant.memory import ConversationMemory
import os
import json
app = Flask(__name__)
# Initialize components
intent_classifier = IntentClassifier()
memories = {} # Store memories by session ID
@app.route('/api/assistant', methods=['POST'])
def process_query():
data = request.json
session_id = data.get('session_id', 'default')
user_input = data.get('query', '')
# Get or create memory for this session
if session_id not in memories:
memories[session_id] = ConversationMemory()
memory = memories[session_id]
# Store in conversation memory
memory.add_user_message(user_input)
# Determine intent and entities
intent, entities = intent_classifier.classify(user_input, memory.get_context())
# Process the intent (same logic as before)
if intent == "weather":
from skills.weather import get_weather
response = get_weather(entities)
elif intent == "calendar":
from skills.calendar_manager import process_calendar_request
response = process_calendar_request(entities)
# Add more intents as needed
else:
from skills.general_knowledge import get_answer
response = get_answer(memory.get_conversation_history())
# Store assistant response in memory
memory.add_assistant_message(response)
# Clean up old sessions occasionally
if len(memories) > 100: # Arbitrary threshold
_cleanup_old_sessions()
return jsonify({
'response': response,
'intent': intent
})
def _cleanup_old_sessions():
"""Remove oldest sessions when we have too many"""
# Implementation depends on how you track session activity
# ...
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)You can deploy this Flask API to a cloud service like AWS, Google Cloud, or Heroku, then develop a simple mobile app that connects to it.
Section 9: Security and Privacy
Security is critical when building a personal assistant that handles sensitive information. Let’s implement some best practices.
First, create a secure configuration manager in utils/config.py:
import os
import json
from cryptography.fernet import Fernet
from dotenv import load_dotenv
class ConfigManager:
def __init__(self, config_file="config.json", encryption_key_env="ENCRYPTION_KEY"):
self.config_file = config_file
load_dotenv()
# Set up encryption
key = os.getenv(encryption_key_env)
if key:
self.cipher = Fernet(key.encode())
self.encryption_enabled = True
else:
self.encryption_enabled = False
print("Warning: Encryption key not found. Sensitive data will be stored unencrypted.")
# Load or create config
self.config = self._load_config()
def _load_config(self):
"""Load configuration from file or create default"""
if os.path.exists(self.config_file):
with open(self.config_file, 'r') as f:
try:
config_data = json.load(f)
# Decrypt sensitive data if encryption is enabled
if self.encryption_enabled and "sensitive" in config_data:
encrypted_data = config_data["sensitive"].encode()
decrypted_data = self.cipher.decrypt(encrypted_data)
config_data["sensitive"] = json.loads(decrypted_data)
return config_data
except json.JSONDecodeError:
print(f"Error: Corrupted config file. Creating new config.")
except Exception as e:
print(f"Error loading config: {str(e)}. Creating new config.")
# Default config
return {
"general": {
"voice_enabled": True,
"personality": "friendly",
"default_location": "New York"
},
"sensitive": {
"user_name": "",
"api_keys": {}
}
}
def save_config(self):
"""Save configuration to file"""
# Create a copy to avoid modifying the original
config_to_save = dict(self.config)
# Encrypt sensitive data if encryption is enabled
if self.encryption_enabled and "sensitive" in config_to_save:
sensitive_data = json.dumps(config_to_save["sensitive"])
encrypted_data = self.cipher.encrypt(sensitive_data.encode())
config_to_save["sensitive"] = encrypted_data.decode()
# Save to file
with open(self.config_file, 'w') as f:
json.dump(config_to_save, f, indent=2)
def get(self, key, default=None):
"""Get a configuration value"""
# Handle nested keys (e.g., "sensitive.api_keys.openai")
keys = key.split('.')
result = self.config
for k in keys:
if isinstance(result, dict) and k in result:
result = result[k]
else:
return default
return result
def set(self, key, value):
"""Set a configuration value"""
keys = key.split('.')
# Navigate to the right level
config = self.config
for i, k in enumerate(keys[:-1]):
if k not in config:
config[k] = {}
config = config[k]
# Set the value
config[keys[-1]] = value
# Save changes
self.save_config()Next, implement user authentication for web or mobile interfaces:
import hashlib
import os
import secrets
import time
from datetime import datetime, timedelta
import jwt
class AuthManager:
def __init__(self, config_manager):
self.config = config_manager
# Ensure auth configuration exists
if not self.config.get("auth"):
self.config.set("auth", {
"salt": secrets.token_hex(16),
"users": {},
"jwt_secret": secrets.token_hex(32),
"token_expiry_hours": 24
})
def register_user(self, username, password):
"""Register a new user"""
users = self.config.get("auth.users", {})
if username in users:
return False, "Username already exists"
# Hash the password with salt
salt = self.config.get("auth.salt")
password_hash = self._hash_password(password, salt)
# Add user
users[username] = {
"password_hash": password_hash,
"created_at": datetime.now().isoformat(),
"last_login": None
}
self.config.set("auth.users", users)
return True, "User registered successfully"
def authenticate(self, username, password):
"""Authenticate a user and return JWT token if successful"""
users = self.config.get("auth.users", {})
if username not in users:
return False, "Invalid username or password"
# Check password
salt = self.config.get("auth.salt")
password_hash = self._hash_password(password, salt)
if users[username]["password_hash"] != password_hash:
return False, "Invalid username or password"
# Update last login
users[username]["last_login"] = datetime.now().isoformat()
self.config.set("auth.users", users)
# Generate token
token = self._generate_token(username)
return True, token
def validate_token(self, token):
"""Validate a JWT token"""
try:
jwt_secret = self.config.get("auth.jwt_secret")
payload = jwt.decode(token, jwt_secret, algorithms=["HS256"])
# Check if token is expired
if time.time() > payload["exp"]:
return False, "Token expired"
# Ensure user still exists
username = payload["sub"]
users = self.config.get("auth.users", {})
if username not in users:
return False, "User does not exist"
return True, username
except jwt.PyJWTError:
return False, "Invalid token"
def _hash_password(self, password, salt):
"""Hash a password with the given salt"""
return hashlib.sha256((password + salt).encode()).hexdigest()
def _generate_token(self, username):
"""Generate a JWT token for the user"""
jwt_secret = self.config.get("auth.jwt_secret")
expiry_hours = self.config.get("auth.token_expiry_hours", 24)
payload = {
"sub": username,
"iat": int(time.time()),
"exp": int(time.time() + expiry_hours * 3600)
}
return jwt.encode(payload, jwt_secret, algorithm="HS256")For API security, implement rate limiting and API key validation:
import time
from functools import wraps
from flask import request, jsonify, g
class RateLimiter:
def __init__(self, requests_per_minute=60):
self.requests_per_minute = requests_per_minute
self.request_history = {} # IP -> list of timestamps
def is_rate_limited(self, ip_address):
"""Check if the IP is currently rate limited"""
current_time = time.time()
# Initialize if new IP
if ip_address not in self.request_history:
self.request_history[ip_address] = []
# Clean up old requests (older than 1 minute)
self.request_history[ip_address] = [
timestamp for timestamp in self.request_history[ip_address]
if current_time - timestamp < 60
]
# Check if rate limit exceeded
if len(self.request_history[ip_address]) >= self.requests_per_minute:
return True
# Add current request
self.request_history[ip_address].append(current_time)
return False
# Flask implementation
rate_limiter = RateLimiter()
def rate_limit_middleware():
"""Apply rate limiting to requests"""
@wraps(f)
def decorated_function(*args, **kwargs):
ip_address = request.remote_addr
if rate_limiter.is_rate_limited(ip_address):
return jsonify({"error": "Rate limit exceeded. Please try again later."}), 429
return f(*args, **kwargs)
return decorated_function
def api_key_required(f):
"""Require API key for protected endpoints"""
@wraps(f)
def decorated_function(*args, **kwargs):
api_key = request.headers.get('X-API-Key')
if not api_key:
return jsonify({"error": "API key is required"}), 401
# Here you would validate against your API keys database
# ...
return f(*args, **kwargs)
return decorated_functionImplement local storage encryption for sensitive data:
from cryptography.fernet import Fernet
import os
import json
class SecureStorage:
def __init__(self, encryption_key=None):
if encryption_key:
self.key = encryption_key
else:
# Generate a key if none provided
self.key = Fernet.generate_key()
with open('encryption.key', 'wb') as key_file:
key_file.write(self.key)
self.cipher = Fernet(self.key)
def encrypt_file(self, data, filename):
"""Encrypt data and save to file"""
# Convert data to JSON string
json_data = json.dumps(data)
# Encrypt
encrypted_data = self.cipher.encrypt(json_data.encode())
# Save to file
with open(filename, 'wb') as file:
file.write(encrypted_data)
def decrypt_file(self, filename):
"""Read and decrypt data from file"""
try:
with open(filename, 'rb') as file:
encrypted_data = file.read()
# Decrypt
decrypted_data = self.cipher.decrypt(encrypted_data)
# Parse JSON
return json.loads(decrypted_data)
except Exception as e:
print(f"Error decrypting file: {str(e)}")
return NoneRemember these security best practices:
- Never store API keys in code or unencrypted files
- Implement proper user authentication for networked deployments
- Use encryption for storing sensitive user data
- Implement rate limiting to prevent abuse
- Keep all dependencies updated to patch security vulnerabilities
- Consider local processing for privacy-sensitive operations
Section 10: Testing and Improvement
Testing is crucial for ensuring your assistant functions correctly and provides a great user experience. Here’s how to implement effective testing and continuously improve your assistant:
Creating Test Scenarios and Benchmarks
Implement unit tests for each component of your assistant:
import unittest
from unittest.mock import MagicMock, patch
from assistant.intent_classifier import IntentClassifier
from skills.weather import get_weather
from assistant.memory import ConversationMemory
class IntentClassifierTests(unittest.TestCase):
def setUp(self):
self.classifier = IntentClassifier()
def test_weather_intent(self):
"""Test weather intent classification"""
text = "What's the weather like in New York?"
intent, entities = self.classifier.classify(text)
self.assertEqual(intent, "weather")
self.assertIn("New York", entities["locations"])Create integration tests with realistic user scenarios:
def test_weather_scenario(self):
"""Test a complete weather query flow"""
test_input = "What's the weather in Seattle tomorrow?"
# Process input
intent, entities = self.intent_classifier.classify(test_input)
# Verify intent classification
if intent != "weather":
return False, f"Expected 'weather' intent but got '{intent}'"
# Call the weather skill and verify response
response = get_weather(entities)
if "Seattle" not in response:
return False, f"Unexpected response: {response}"
return True, "Weather scenario completed successfully"Establish benchmark metrics:
- Response time (aim for < 1 second)
- Intent classification accuracy (> 95% for core intents)
- Entity extraction precision and recall
- Overall task completion rate
A/B Testing Different NLP Approaches
Compare different NLP libraries and approaches:
class ABTester:
def __init__(self):
# Initialize different NLP approaches
self.spacy_classifier = SpacyIntentClassifier()
self.transformer_classifier = TransformerIntentClassifier()
self.custom_classifier = CustomRuleIntentClassifier()
def compare_classifiers(self, test_data):
"""Compare performance of different classifiers on test data"""
results = {}
for name, classifier in [
("spacy", self.spacy_classifier),
("transformer", self.transformer_classifier),
("custom_rules", self.custom_classifier)
]:
# Test each classifier
correct = 0
start_time = time.time()
for text, expected_intent in test_data:
intent, _ = classifier.classify(text)
if intent == expected_intent:
correct += 1
elapsed = time.time() - start_time
results[name] = {
"accuracy": correct / len(test_data),
"avg_time_ms": (elapsed * 1000) / len(test_data)
}
return resultsGathering and Implementing User Feedback
Implement a simple feedback system:
class FeedbackCollector:
def record_feedback(self, user_input, assistant_response, rating, comments=None):
"""Record user feedback for an interaction"""
entry = {
"timestamp": datetime.now().isoformat(),
"user_input": user_input,
"assistant_response": assistant_response,
"rating": rating,
"comments": comments
}
# Append to feedback file
with open(self.feedback_file, 'a') as f:
f.write(json.dumps(entry) + '\n')Add feedback prompts after responses:
def get_feedback():
"""Ask for user feedback after completing a task"""
print("\nWas that helpful? (1-5, where 5 is most helpful)")
try:
rating = int(input("> "))
if 1 <= rating <= 5:
return rating
return None
except ValueError:
return NoneContinuous Learning and Improvement
Implement analytics to identify patterns:
def analyze_usage(self, days=7):
"""Analyze usage patterns from the logs"""
# Read and filter log entries
entries = self._get_recent_entries(days)
# Analyze intents
intent_counts = self._count_intents(entries)
# Analyze response times
response_times = [entry["response_time_ms"] for entry in entries]
avg_response_time = sum(response_times) / len(response_times)
# Identify failed queries
failed_queries = [
entry["user_input"] for entry in entries
if "sorry" in entry["response"].lower() or
"don't understand" in entry["response"].lower()
]
return {
"total_queries": len(entries),
"intent_distribution": intent_counts,
"average_response_time_ms": avg_response_time,
"failed_queries": failed_queries[:10]
}Use failure patterns to improve your assistant:
- Review the most common failed queries
- Create new intents for frequently misclassified inputs
- Expand entity recognition for missed terms
- Add new skills based on user feedback
- Regularly update language models and external APIs
Section 11: Advanced Features
Once your basic assistant is working reliably, you can enhance it with advanced features:
Adding Computer Vision Capabilities
Integrate computer vision to recognize objects or interpret images:
from PIL import Image
import pytesseract
import cv2
import numpy as np
class VisionHandler:
def __init__(self):
# Initialize computer vision components
pass
def extract_text_from_image(self, image_path):
"""Extract text from an image using OCR"""
image = Image.open(image_path)
text = pytesseract.image_to_string(image)
return text
def identify_objects(self, image_path):
"""Identify objects in an image"""
# Load pre-trained model
net = cv2.dnn.readNetFromCaffe(
'models/MobileNetSSD_deploy.prototxt',
'models/MobileNetSSD_deploy.caffemodel'
)
# Load image
image = cv2.imread(image_path)
(h, w) = image.shape[:2]
# Process image
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843, (300, 300), 127.5)
net.setInput(blob)
detections = net.forward()
# Parse results
results = []
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.2: # Confidence threshold
idx = int(detections[0, 0, i, 1])
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# Get class label
CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
label = CLASSES[idx]
results.append((label, confidence))
return resultsHome Automation Integration
Connect your assistant to smart home devices:
class HomeAutomation:
def __init__(self):
# Initialize connections to home automation systems
self.hue_bridge = None
self.nest_thermostat = None
self.smart_plugs = {}
# Connect to Philips Hue
self._connect_to_hue()
# Connect to smart thermostats
self._connect_to_nest()
# Connect to smart plugs
self._connect_to_smart_plugs()
def control_lights(self, room, action, brightness=None, color=None):
"""Control lights in a specific room"""
if not self.hue_bridge:
return "Hue Bridge not connected"
try:
# Get lights in the room
room_lights = self._get_room_lights(room)
if action.lower() == "on":
for light in room_lights:
self.hue_bridge.set_light(light, 'on', True)
if brightness:
self.hue_bridge.set_light(light, 'bri', brightness)
if color:
self.hue_bridge.set_light(light, 'hue', self._color_to_hue(color))
return f"Turned on lights in {room}"
elif action.lower() == "off":
for light in room_lights:
self.hue_bridge.set_light(light, 'on', False)
return f"Turned off lights in {room}"
else:
return f"Unknown action: {action}"
except Exception as e:
return f"Error controlling lights: {str(e)}"
def set_temperature(self, target_temp):
"""Set thermostat temperature"""
if not self.nest_thermostat:
return "Thermostat not connected"
try:
self.nest_thermostat.set_temperature(target_temp)
return f"Set temperature to {target_temp}°F"
except Exception as e:
return f"Error setting temperature: {str(e)}"Multi-language Support
Add support for multiple languages:
from googletrans import Translator
import langdetect
class MultiLanguageHandler:
def __init__(self):
self.translator = Translator()
self.default_language = "en"
def detect_language(self, text):
"""Detect the language of input text"""
try:
language = langdetect.detect(text)
return language
except:
return self.default_language
def translate_to_english(self, text):
"""Translate text to English for processing"""
try:
language = self.detect_language(text)
if language == "en":
return text, language
translated = self.translator.translate(text, dest="en")
return translated.text, language
except Exception as e:
print(f"Translation error: {str(e)}")
return text, "en"
def translate_response(self, text, target_language):
"""Translate response back to original language"""
try:
if target_language == "en":
return text
translated = self.translator.translate(text, dest=target_language)
return translated.text
except Exception as e:
print(f"Translation error: {str(e)}")
return textIntegrate this into your main assistant:
def process_input(self, user_input):
# Detect and translate if needed
english_text, source_language = self.language_handler.translate_to_english(user_input)
# Process with your existing pipeline
intent, entities = self.intent_classifier.classify(english_text)
response = self._get_response_for_intent(intent, entities)
# Translate response back
if source_language != "en":
response = self.language_handler.translate_response(response, source_language)
return responseEmotion Detection from Voice
Add emotion recognition to better understand user context:
import librosa
import numpy as np
from tensorflow.keras.models import load_model
class EmotionDetector:
def __init__(self, model_path="models/emotion_model.h5"):
self.model = load_model(model_path)
self.emotions = ["angry", "happy", "neutral", "sad", "surprised"]
def extract_features(self, audio_file):
"""Extract audio features for emotion detection"""
try:
# Load audio file
y, sr = librosa.load(audio_file, sr=None)
# Extract features
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
chroma = librosa.feature.chroma_stft(y=y, sr=sr)
mel = librosa.feature.melspectrogram(y=y, sr=sr)
contrast = librosa.feature.spectral_contrast(y=y, sr=sr)
tonnetz = librosa.feature.tonnetz(y=y, sr=sr)
# Combine features
features = np.concatenate((
np.mean(mfccs, axis=1),
np.mean(chroma, axis=1),
np.mean(mel, axis=1),
np.mean(contrast, axis=1),
np.mean(tonnetz, axis=1)
))
return features.reshape(1, -1)
except Exception as e:
print(f"Error extracting features: {str(e)}")
return None
def detect_emotion(self, audio_file):
"""Detect emotion from audio file"""
features = self.extract_features(audio_file)
if features is None:
return "neutral"
# Predict emotion
prediction = self.model.predict(features)
emotion_idx = np.argmax(prediction)
return self.emotions[emotion_idx]Conclusion
Congratulations! You’ve built a sophisticated personal AI assistant capable of understanding natural language, performing useful tasks, and continuously improving.
Recap of What You’ve Built
Your assistant now includes:
- Speech recognition and text-to-speech capabilities
- Natural language understanding with intent classification and entity extraction
- Calendar management, weather forecasting, and web search
- Integration with AI models for enhanced conversations
- A secure, privacy-focused design
- Testing frameworks for continuous improvement
- Advanced capabilities like computer vision and home automation
Resources for Further Learning
To continue enhancing your assistant:
- Books and Courses:
- “Natural Language Processing with Python” by Bird, Klein, and Loper
- “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Géron
- Fast.ai’s NLP course (https://www.fast.ai/)
- Libraries and Frameworks:
- spaCy (https://spacy.io/) for advanced NLP
- Rasa (https://rasa.com/) for conversation management
- PyTorch or TensorFlow for deep learning models
- APIs and Services:
- OpenAI GPT models for enhanced conversational abilities
- Google Speech-to-Text and Text-to-Speech for improved voice interfaces
- Cloud services like AWS, Google Cloud, or Azure for scaling
Community Support Options
Join these communities to share ideas and get help:
- Forums:
- Stack Overflow – Tag your questions with relevant libraries
- Reddit communities like r/MachineLearning and r/NLP
- GitHub:
- Contribute to open-source assistant frameworks
- Share your code and get feedback
- Discord and Slack:
- Join AI/ML communities like Hugging Face’s Discord
- Find local tech meetups focused on AI assistants
Ideas for Extending Your Assistant’s Capabilities
Consider these extensions for your next iterations:
- Personalization:
- Add user profiles with preferences and history
- Implement learning from user interactions
- Multimodal Interactions:
- Add a camera for facial recognition and expression analysis
- Implement gesture recognition for control
- IoT Integration:
- Connect to more smart home devices
- Build DIY sensors for environmental monitoring
- Advanced Processing:
- Implement on-device ML for privacy and latency improvement
- Add specialized domain knowledge for your interests
Appendix
Troubleshooting Common Issues
Speech Recognition Problems:
def troubleshoot_speech_recognition():
"""Check common speech recognition issues"""
# Test microphone
import pyaudio
p = pyaudio.PyAudio()
info = p.get_host_api_info_by_index(0)
num_devices = info.get('deviceCount')
for i in range(num_devices):
if p.get_device_info_by_host_api_device_index(0, i).get('maxInputChannels') > 0:
print(f"Input Device {i}: {p.get_device_info_by_host_api_device_index(0, i).get('name')}")
# Check network connectivity for cloud-based speech recognition
import requests
try:
response = requests.get("https://www.google.com", timeout=5)
print(f"Network connectivity: OK ({response.status_code})")
except requests.exceptions.RequestException:
print("Network connectivity: Failed - check your internet connection")NLP and Intent Classification Issues:
- Verify training data quality and quantity
- Check for imbalanced intent classes
- Review entity extraction patterns
- Validate model performance on edge cases
API Integration Problems:
- Verify API keys and credentials
- Check API rate limits and quotas
- Implement robust error handling
- Add retry logic for transient failures
Performance Optimization Tips
Speed Up Response Time:
# Cache frequent responses
from functools import lru_cache
@lru_cache(maxsize=128)
def get_weather_cached(location, date):
"""Cached weather data to reduce API calls"""
# Only call API if not in cache
return actual_weather_api_call(location, date)Reduce Memory Usage:
- Use generators for large datasets
- Implement lazy loading for models
- Clean up resources when not in use
- Profile memory usage regularly
Optimize NLP Pipeline:
- Use smaller models for simple tasks
- Implement pipeline batching
- Pre-process and cache common phrases
- Use rule-based shortcuts for frequent commands
Sample Code Snippets for Key Components
Wake Word Detection:
import pvporcupine
def setup_wake_word_detection(keywords=["hey assistant"], sensitivities=[0.5]):
"""Set up wake word detection using Porcupine"""
porcupine = pvporcupine.create(keywords=keywords, sensitivities=sensitivities)
# Access microphone
pa = pyaudio.PyAudio()
audio_stream = pa.open(
rate=porcupine.sample_rate,
channels=1,
format=pyaudio.paInt16,
input=True,
frames_per_buffer=porcupine.frame_length
)
return porcupine, audio_stream, pa
def detect_wake_word(porcupine, audio_stream):
"""Listen for wake word and return True if detected"""
pcm = audio_stream.read(porcupine.frame_length)
pcm = struct.unpack_from("h" * porcupine.frame_length, pcm)
keyword_index = porcupine.process(pcm)
return keyword_index >= 0Conversation Memory Management:
class ConversationMemory:
def __init__(self, max_turns=10):
self.max_turns = max_turns
self.messages = []
self.context = {}
def add_message(self, role, content):
"""Add a message to the conversation history"""
self.messages.append({"role": role, "content": content})
# Trim if exceeding max turns
if len(self.messages) > self.max_turns * 2: # Each turn is user + assistant
self.messages = self.messages[-self.max_turns * 2:]
def get_conversation_for_llm(self):
"""Format conversation history for LLM context"""
return [
{"role": msg["role"], "content": msg["content"]}
for msg in self.messages
]
def update_context(self, key, value):
"""Update context with key information"""
self.context[key] = value
def get_context(self, key=None):
"""Get specific context or all context"""
if key:
return self.context.get(key)
return self.contextRecommended Hardware Specifications
For a reliable personal assistant experience:
Desktop/Laptop:
- CPU: Intel i5/Ryzen 5 or better
- RAM: 8GB minimum, 16GB recommended
- Storage: 256GB SSD minimum
- Microphone: Decent quality USB microphone for better speech recognition
- Speakers: Clear audio output
Raspberry Pi Deployment:
- Raspberry Pi 4 with 4GB RAM minimum
- 32GB+ microSD card (Class 10)
- USB microphone array
- Speaker or audio output device
- Optional: Battery pack for portability
Optional Hardware:
- Camera: For computer vision features
- Smart home hub: For home automation
- Additional sensors: Temperature, humidity, motion
- Touch screen: For visual interface
Good luck!
Other Articles






No Comment! Be the first one.